10年专注于企业数字化应用开发,秉承创新、卓越和客户至上的核心价值观,致力于为客户提供优质的数字化解决方案
10年专注于企业数字化应用开发,秉承创新、卓越和客户至上的核心价值观,致力于为客户提供优质的数字化解决方案


在企业数字化运营中,数据采集软件不仅要 “采得准”,更要 “处理得好、存得安全”。其数据处理与存储环节,是将原始数据转化为可用资产的核心链路,直接决定数据价值的发挥效率。从数据清洗到结构化存储,每个步骤都需遵循严谨的技术逻辑,适配企业多样化的业务需求。
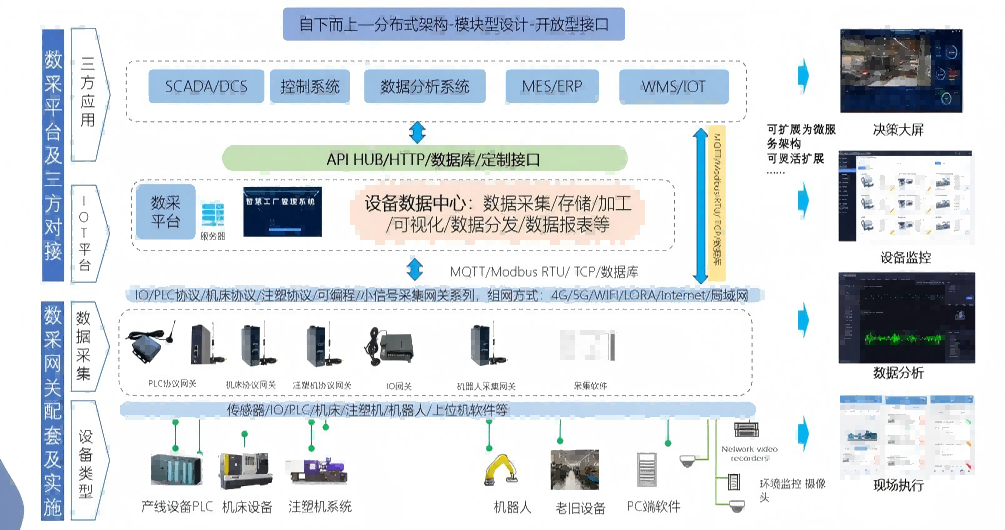
一、数据处理:从 “杂乱原始” 到 “规整可用”
数据采集软件的处理环节,本质是解决 “原始数据不规范” 问题,通过多维度加工,让数据具备分析与应用价值,主要分为三个核心步骤:
1. 数据清洗:剔除无效信息,保障数据准确性
原始采集的数据常包含冗余、错误或缺失内容,例如从电商平台采集的用户评论中,可能夹杂乱码、重复留言,或部分字段(如用户评分)为空。软件通过预设规则自动清洗:一是去重处理,基于用户 ID、评论时间等唯一标识,删除重复数据;二是纠错修复,对格式错误的信息(如手机号少位、日期格式混乱),按行业标准自动补全或标记异常;三是缺失值处理,对关键字段缺失的数据,采用 “默认填充”(如用 “未知” 补充缺失的用户地域)或 “样本剔除”,避免影响后续分析。
2. 数据转换:统一格式,适配业务场景
不同数据源的格式差异较大,例如从 ERP 系统采集的销售数据为 “Excel 表格”,从社交媒体采集的用户行为数据为 “JSON 格式”。软件通过格式标准化,将多源数据统一转换为企业常用格式(如 CSV、Parquet);同时进行数据结构化,把非结构化数据(如用户语音评论、产品图片)转化为结构化信息 —— 例如通过语音转文字技术提取评论关键词,用图像识别标注产品特征,让原本无法直接分析的数据变得可量化。
3. 数据整合:关联多维度信息,构建完整数据链路
单一维度的数据价值有限,软件需将分散数据关联整合。例如零售企业采集的 “用户购买记录”“商品库存数据”“物流信息”,会通过 “订单号” 这一共同标识串联,形成 “用户 - 商品 - 物流” 的完整链路。整合过程中,软件还会进行数据计算,生成衍生指标(如 “单客平均消费额”“商品周转率”),直接为业务分析提供支撑。
二、数据存储:兼顾 “安全稳定” 与 “高效调用”
数据处理完成后,软件需通过合理的存储方案,平衡 “长期安全保存” 与 “快速查询使用” 的需求,常见两种存储模式适配不同场景:
1. 关系型数据库:适配结构化数据,保障数据一致性
对于规整的结构化数据(如企业客户信息、财务报表),软件优先采用 MySQL、Oracle 等关系型数据库存储。这类数据库通过 “表结构” 明确数据字段间的关联关系,例如 “客户表” 与 “订单表” 通过 “客户 ID” 关联,支持复杂的多表查询,同时具备 “事务管理” 功能 —— 若某笔订单数据存储时突发故障,系统会自动回滚,避免数据缺失或错乱,适合对数据准确性要求极高的场景(如财务数据存储)。
2. 非关系型数据库:适配海量非结构化数据,提升存储效率
当企业需存储海量非结构化或半结构化数据(如用户行为日志、短视频素材),软件会选择 MongoDB、HBase 等非关系型数据库。这类数据库无需预设固定表结构,可灵活存储不同格式的数据,且支持分布式存储 —— 将数据分散在多台服务器,既解决 “单台服务器存储上限” 问题,又能通过 “分片查询” 提升数据调用速度。例如电商企业采集的 “用户实时浏览日志”,每秒产生数万条数据,非关系型数据库可快速接收并存储,同时支持按 “时间段”“用户 ID” 快速筛选查询。
3. 存储安全:多层防护,规避数据风险
软件还会通过多重措施保障数据安全:一是权限管控,设置不同角色的访问权限(如普通员工仅能查询数据,管理员可修改配置),避免数据泄露;二是数据备份,采用 “本地 + 云端” 双备份模式,定期自动备份数据,防止硬件故障导致数据丢失;三是加密处理,对敏感数据(如用户身份证号、银行卡信息)进行传输加密与存储加密,符合《数据安全法》等法规要求。
数据处理与存储,是数据采集软件发挥价值的 “中转站”。通过规范的处理流程,解决数据 “用不了” 的问题;通过灵活的存储方案,解决数据 “存不下、调不快” 的难题。对企业而言,选择具备完善处理与存储能力的软件,才能让采集的数据真正成为支撑业务决策、驱动增长的核心资产。